Data Collection
Explore This Issue
November 2025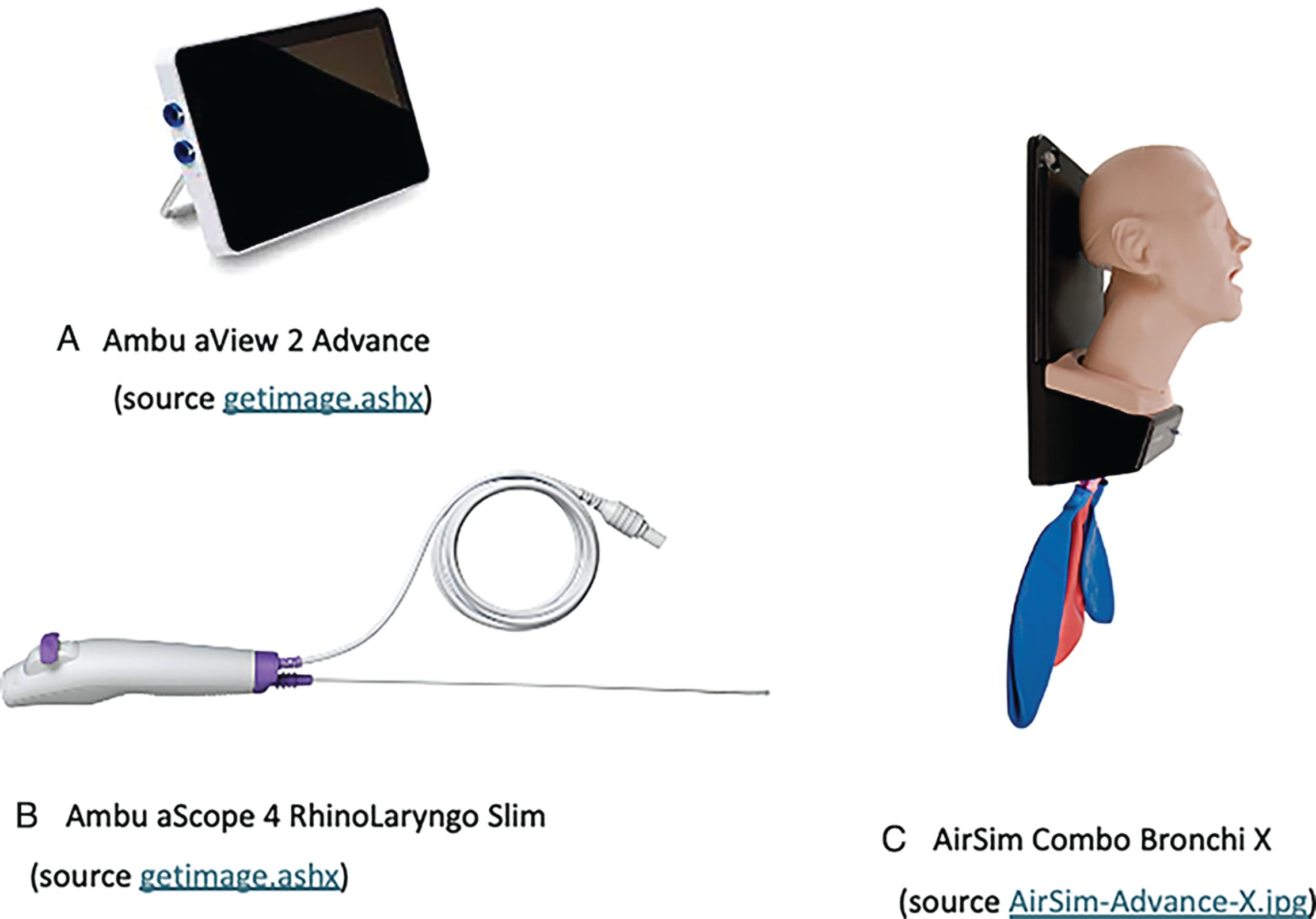
Figure 1. Setup for pilot testing of machine learning copilot. Panel A: Ambu aView 2 Advance; Panel B: Ambu
aScope 4 RhinoLaryngo Slim; Panel C: AirSim Combo Bronchi X.
The training data were collected by performing FFL on an AirSim Combo Bronchi X manikin (Fig. 1) (United Kingdom, TruCorp Ltd) using an Ambu aScope 4 RhinoLaryngo Slim (Fig. 1) connected to an Ambu aView 2 Advance Displaying Unit (Ballerup, Ambu A/S) (Fig. 1).
Data for training both models were selected from a dataset that was generated by performing 20 flexible laryngoscopies on the manikin. All scoping videos were performed by a single, experienced otolaryngologist on an Ambu aScope 4 RhinoLaryngo Slim (Fig. 1). Various levels of expertise were simulated when recording videos to ensure that a variety of angles and views were captured. The FFL AI Copilot was trained on the left nasal cavity only to keep the machine learning consistent and prevent confusion or misclassification of structures based on sidedness.
Anatomical Region Classifier
The anatomical region classifier was used to identify the physical location of the camera at the time of image capture. The classes used were Larynx, Nasal Cavity, Nasopharynx, Oropharynx, Out of Body, and Whiteout. Videos were split into image frames, and each image was assigned to a class by a trained graduate student. The classes were defined in the manikin model as follows:
- Out of body: Any image from outside of the manikin.
- Nasal cavity: The scope had entered the manikin but had not yet moved past the posterior nasal septum.
- Nasopharynx: Between the distal-most end of the septum, but not yet past a clear delineation in the material where the velum would be in a human.
- Oropharynx: Past the velum delineation but not yet past the superior border of the epiglottis.
- Larynx: Past the superior edge of the epiglottis but not yet through the vocal folds to the trachea.
- Whiteout: The scope was too close to the mucosa such that the image was 80% red or whited out, and a human observer could not reasonably determine where the scope was currently located without information from previous frames.
In total, there were 56,262 images in the anatomical region dataset. They were broken down into 42,971 training images, 3,596 validation images, and 9,695 testing images. To prevent data leakage due to the high correlation between consecutive frames, each video and all its images were assigned exclusively to a single split: train, validation, or test.
Leave a Reply